|
Hypersim: A Photorealistic Synthetic Dataset for Holistic Indoor Scene Understanding |
|
Nathan Paczan |
Russ Webb |
Joshua M. Susskind |
|
Apple |
|
International Conference on Computer Vision (ICCV) 2021 |

|
|
Figure 1: Overview of the Hypersim dataset. For each color image (a), Hypersim includes the following ground truth layers: depth (b); surface normals (c); instance-level semantic segmentations (d,e); diffuse reflectance (f); diffuse illumination (g); and a non-diffuse residual image that captures view-dependent lighting effects like glossy surfaces and specular highlights (h). Our diffuse reflectance, diffuse illumination, and non-diffuse residual layers are stored as HDR images, and can be composited together to exactly reconstruct the color image. Our dataset also includes complete scene geometry, material information, and lighting information for every scene. |
|
|
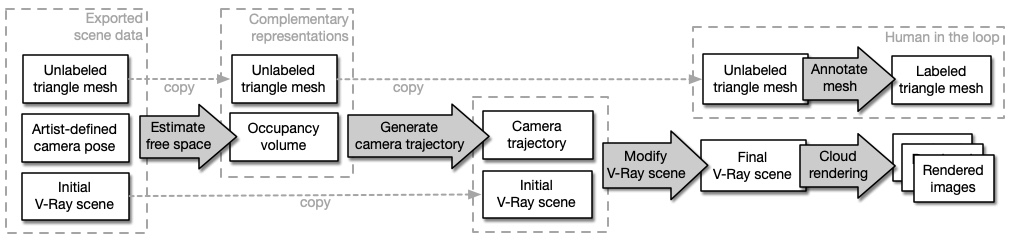
Figure 2: Overview of our computational pipeline. In this simplified diagram, our pipeline takes as input a triangle mesh, an artist-defined camera pose, and a V-Ray scene description file, and produces as output a collection of images with ground truth labels and corresponding geometry. The main steps of our pipeline are as follows. We estimate the free space in our scene, use this estimate to generate a collision-free camera trajectory, modify our V-Ray scene to include the trajectory, and invoke our cloud rendering system to render images. In parallel with the rest of our pipeline, we annotate the scene’s triangle mesh using our interactive tool. In a post-processing step, we propagate mesh annotations to our rendered images (not shown). This pipeline design enables us to render images before mesh annotation is complete, and also enables us to re-annotate our scenes (e.g., with a different set of labels) without needing to re-render images. |

|
|
Figure 3: Randomly selected images from our dataset. From these images, we see that the scenes in our dataset are diverse, and our view sampling heuristic generates informative views without requiring our scenes to be semantically labeled. |
|
|
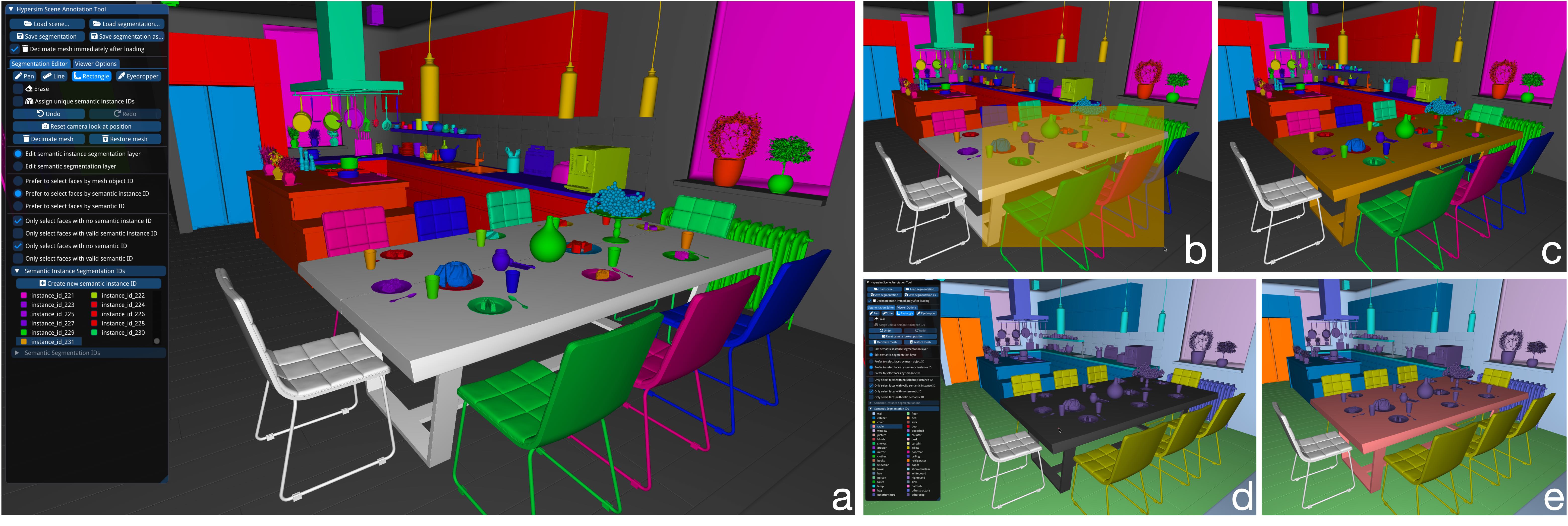
Figure 4: Our interactive mesh annotation tool. Our tool has a semantic instance view (a,b,c) and a semantic label view (d,e), as well as a set of selection filters that can be used to limit the extent of editing operations based on the current state of the mesh. To see how these filters can be useful, consider the following scenario. The table in this scene is composed of multiple object parts, but initially, these object parts have not been grouped into a semantic instance (a). Our filters enable the user to paint the entire table by drawing a single rectangle, without disturbing the walls, floor, or other objects (b,c). Once the table has been grouped into an instance, the user can then apply a semantic label with a single button click (d,e). Parts of the mesh that have not been painted in either view are colored white (e.g., the leftmost chair). Parts of the mesh that have not been painted in the current view, but have been painted in the other view, are colored dark grey, (e.g., the table in (d)). Our tool enables the user to accurately annotate an input mesh with very rough painting gestures. |

|
|
Figure 5: We include a tight 9-DOF bounding box for each semantic instance, so that our dataset can be applied directly to 3D object detection problems. |
|
|
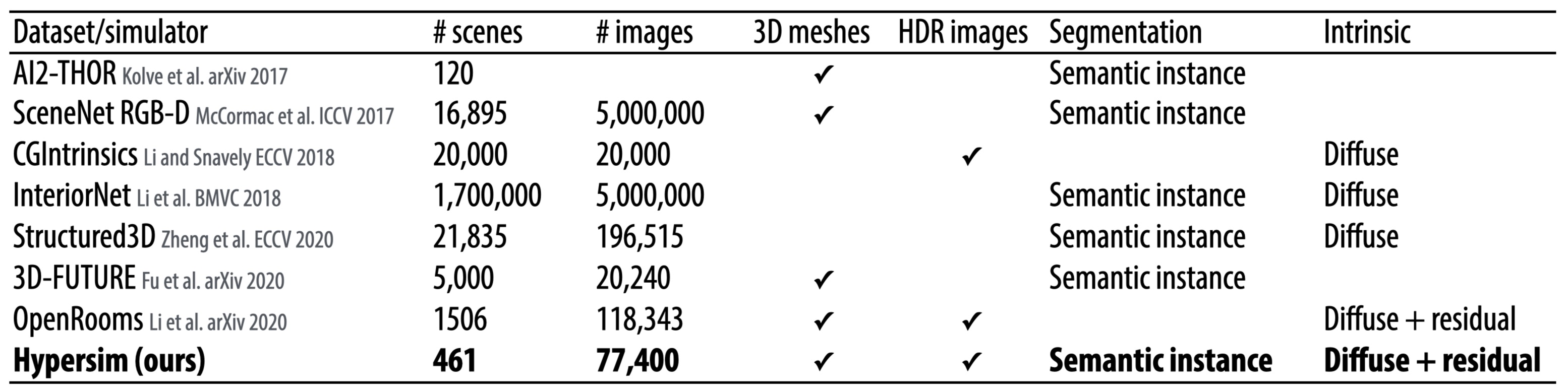
Table 1: Comparison to previous datasets and simulators for indoor scene understanding. We limit our comparisons to synthetic datasets and simulators that aim to be photorealistic. The "3D meshes" column indicates whether or not 3D assets (e.g., triangle meshes) are publicly available. The "HDR images" column indicates whether or not images are available in an unclamped HDR format. The "Segmentation" column indicates what type of segmentation information is available. The "Intrinsic" column indicates how images are factored into disentangled lighting and shading components. Our dataset is the first to include 3D assets, HDR images, semantic instance segmentations, and a disentangled image representation. |
Abstract: For many fundamental scene understanding tasks, it is difficult or impossible to obtain per-pixel ground truth labels from real images. We address this challenge by introducing Hypersim, a photorealistic synthetic dataset for holistic indoor scene understanding. To create our dataset, we leverage a large repository of synthetic scenes created by professional artists, and we generate 77,400 images of 461 indoor scenes with detailed per-pixel labels and corresponding ground truth geometry. Our dataset: (1) relies exclusively on publicly available 3D assets; (2) includes complete scene geometry, material information, and lighting information for every scene; (3) includes dense per-pixel semantic instance segmentations and complete camera information for every image; and (4) factors every image into diffuse reflectance, diffuse illumination, and a non-diffuse residual term that captures view-dependent lighting effects.
We analyze our dataset at the level of scenes, objects, and pixels, and we analyze costs in terms of money, computation time, and annotation effort. Remarkably, we find that it is possible to generate our entire dataset from scratch, for roughly half the cost of training a popular open-source natural language processing model. We also evaluate sim-to-real transfer performance on two real-world scene understanding tasks - semantic segmentation and 3D shape prediction - where we find that pre-training on our dataset significantly improves performance on both tasks, and achieves state-of-the-art performance on the most challenging Pix3D test set. All of our rendered image data, as well as all the code we used to generate our dataset and perform our experiments, is available online.
@inproceedings{roberts:2021,
author = {Mike Roberts AND Jason Ramapuram AND Anurag Ranjan AND Atulit Kumar AND
Miguel Angel Bautista AND Nathan Paczan AND Russ Webb AND Joshua M. Susskind},
title = {{Hypersim}: {A} Photorealistic Synthetic Dataset for Holistic Indoor Scene Understanding},
booktitle = {International Conference on Computer Vision (ICCV) 2021},
year = {2021}
}
Acknowledgements: We thank the professional artists at Evermotion for making their Archinteriors Collection available for purchase; Danny Nahmias for helping us to acquire data; Max Horton for helping us to prototype our annotation tool; Momchil Lukanov and Vlado Koylazov at Chaos Group for their excellent support with V-Ray; David Antler, Hanlin Goh, and Brady Quist for proofreading the paper; Ali Farhadi, Zhile Ren, Fred Schaffalitzky, Qi Shan, Josh Susskind, and Russ Webb for the helpful discussions; and Jia Zheng for catching and correcting an error in Table 1.